

Overview:
In the distributed systems, we enable loose coupling between systems by passing messages via a service bus / message queue. We had implemented that in one of the architectural pattern series here. Sometimes, when the message throughout is extremely high – that is number of the incoming messages per unit time is greater than the number of messages processed per unit time – then queue will end up holding infinite number of messages. The message queue might fail eventually due to Out Of Memory error and clients might never receive the response for the messages they had sent! To avoid this, if we plan to run N number of servers always and if we never receive any message, then we will end up paying for these unused servers.
The cost effective solution would be auto-scaling! This concept is nothing new. In this article, we are going to scale message-consumers out / in based on the CPU utilization in a Kubernetes cluster. This way when 1 server is struggling to process all the messages, we bring additional servers to speed up the process to reduce the load on the single server and balance the workload.
Sample Application:
- I am going to reuse the application which we had used before here. Check that out for better understanding.
- Our application is going to place some tasks into a message queue as and when the requests arrive.
- Tasks are going to be finding the Nth position in the Fibonacci series! I am going to use 2^N algorithm to make the process very slow.
- There will be some categories like LOW, HIGH, URGENT to prioritize the tasks. Obviously URGENT tasks should be done first!
- Task-executor is a message processor to consume the messages. By default we will have 1 message processor up and running always.
- But 1 node might not be enough sometimes.
- Based on the CPU utilization, our auto-scaler will bring additional Pods up.
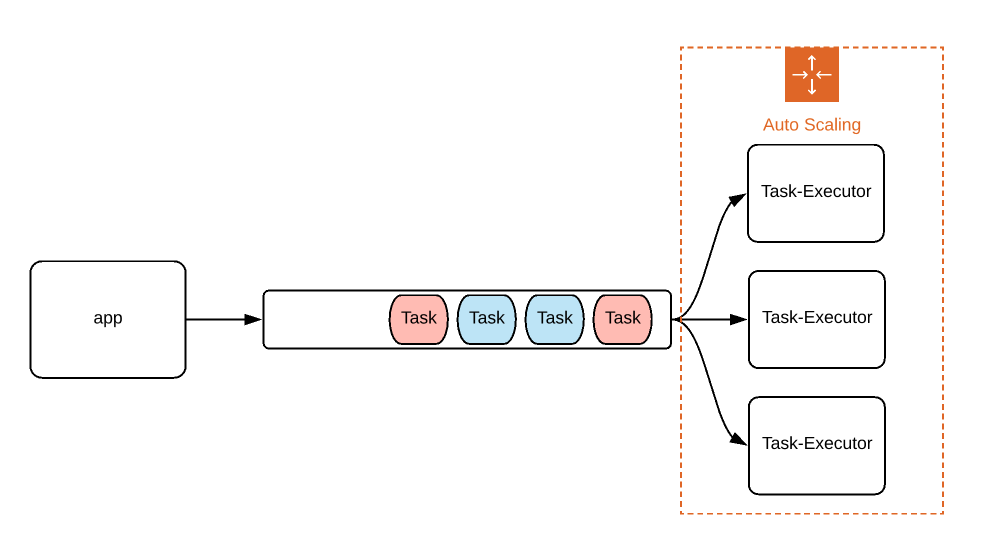

Advantages:
This approach has several advantages.
- Loose coupling between producers and consumers.
- We can dynamically scale out or scale in based on the demand. (In this article, we use CPU utilization. We could also use based on the messages count in the queue)
- Reliable
- Load leveling. A single server is not responsible for processing all the messages. Load is distributed among multiple message processors/consumers.
Kubernetes Resources:
- We would be creating resources as shown in this picture.
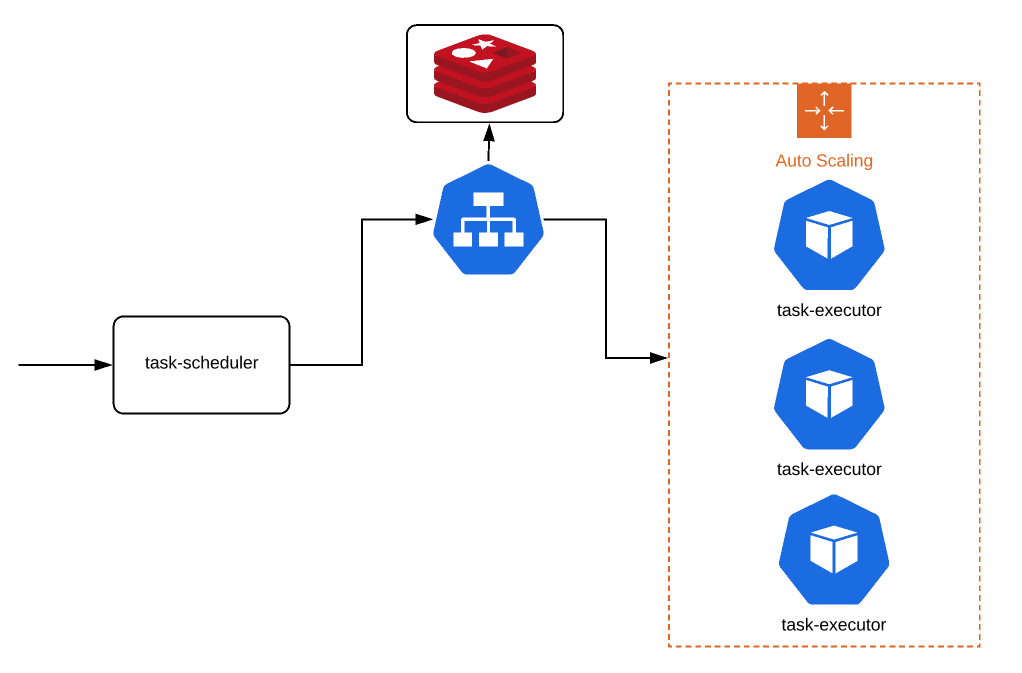

- redis
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: redis-master
name: redis-master
spec:
replicas: 1
selector:
matchLabels:
app: redis-master
template:
metadata:
labels:
app: redis-master
spec:
containers:
- image: redis
name: redis-master
ports:
- containerPort: 6379
---
apiVersion: v1
kind: Service
metadata:
labels:
app: redis-master
name: redis-master
spec:
ports:
- name: redis-port
port: 6379
protocol: TCP
targetPort: 6379
selector:
app: redis-master
type: ClusterIP- task-scheduler
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: task-scheduler
name: task-scheduler
spec:
replicas: 1
selector:
matchLabels:
app: task-scheduler
template:
metadata:
labels:
app: task-scheduler
spec:
containers:
- image: vinsdocker/task-scheduler
name: task-scheduler
env:
- name: REDIS_HOST
value: redis-master
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
labels:
app: task-scheduler
name: task-scheduler
spec:
ports:
- name: task-scheduler
port: 8080
protocol: TCP
targetPort: 8080
nodePort: 32001
selector:
app: task-scheduler
type: NodePort- task-executor
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: task-executor
name: task-executor
spec:
replicas: 1
selector:
matchLabels:
app: task-executor
template:
metadata:
labels:
app: task-executor
spec:
containers:
- image: vinsdocker/task-executor
name: task-executor
env:
- name: REDIS_HOST
value: redis-master
resources:
requests:
cpu: 200m
memory: 512Mi- Horizontal Pod Autoscaler (HPA):
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: task-executor
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: task-executor
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50Resource Utilization:
- When there is no load, the CPU/Memory utilization of the cluster is more or less like this.
NAME CPU(cores) MEMORY(bytes)
redis-master-65f7f8cf88-8tqxm 3m 2Mi
task-executor-7dd8855487-2gzbf 4m 184Mi
task-scheduler-86d64c5598-kd6sr 3m 192Mi- The HPA output is as shown here (kubectl get hpa).
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
task-executor Deployment/task-executor 3%/50% 1 3 1 5m- I send hundreds of messages to the task-scheduler and wait for 2 mins.
- I can see the CPU utilization increase and number of task-executors increase from 1 to 3.
// kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
task-executor Deployment/task-executor 205%/50% 1 3 3 7m
// kubectl top pods
NAME CPU(cores) MEMORY(bytes)
redis-master-65f7f8cf88-8tqxm 5m 3Mi
task-executor-7dd8855487-2gzbf 526m 176Mi
task-executor-7dd8855487-5897f 489m 176Mi
task-executor-7dd8855487-t8tbp 512m 179Mi
task-scheduler-86d64c5598-kd6sr 3m 189Mi- Once the messages are processed, wait for 5 mins and kubernetes will scale these consumers in and only one instance will be up and running.
Summary:
We were able to successfully demonstrate the auto-scaling the message consumers based on the CPU utilization to achieve load leveling, loose coupling and speeding up the message processing.
Happy coding 🙂
{kind=link}