



Overview:
This is a 3rd part in the Kafka series. If you have not read the previous articles, I would encourage you to read those in the below order.
- Kafka – Local Infrastructure Setup Using Docker Compose
- Kafka – Creating Simple Producer & Consumer Applications Using Spring Boot
We had already seen producing messages into a Kafka topic and the messages being processed by a consumer. As long as the producer and the consumer are doing things in the same rate or producer producing messages per unit time is less than the consumers processing messages per unit time, We should be good. What if the consumer is slower than the producer?!! Lets say, A producer produces a message every second. But a consumer takes 2 seconds to process a message. Now in 10 seconds, we would have had 10 messages and 5 of them would have been processed by the consumer. So the consumer could never catch up or process all the messages. Eventually we will have infinite number of messages in the Kafka topic which is NOT good.
In this article, We would see how to scale the consumers when the consumers processing rates are lesser compared to producers.
Partitions & Consumer Group:
As I had mentioned in the previous articles, Topic is made up of partitions. Partitions decide the max number of consumers you can have in a group.
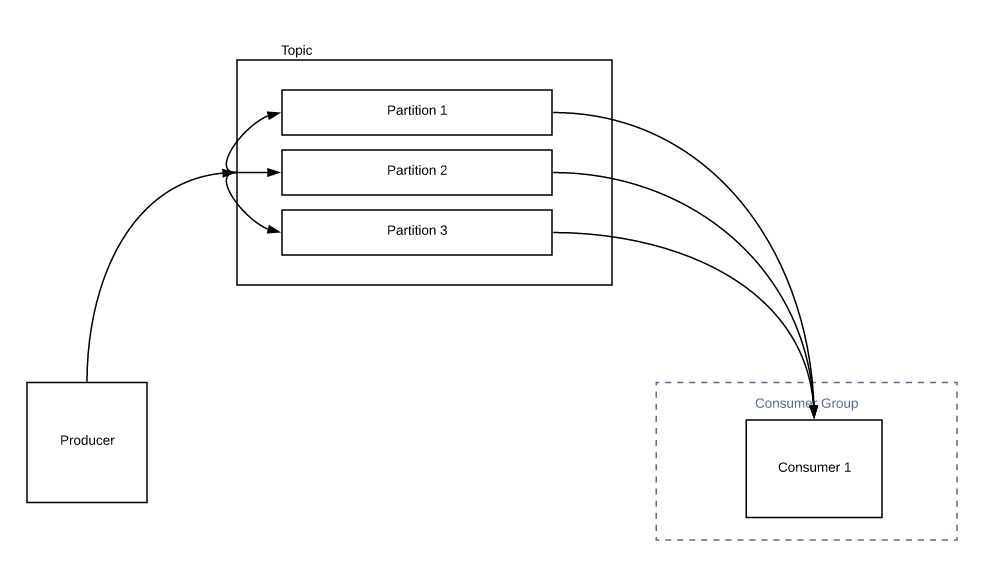

In the above picture, we have only one consumer. It can read all the messages from all the partitions. When you increase the number of consumers in the group, partition reassignment happens and instead of consumer 1 reading all the messages from all the partitions, consumer 2 could share some of the load with consumer 1 as shown below.
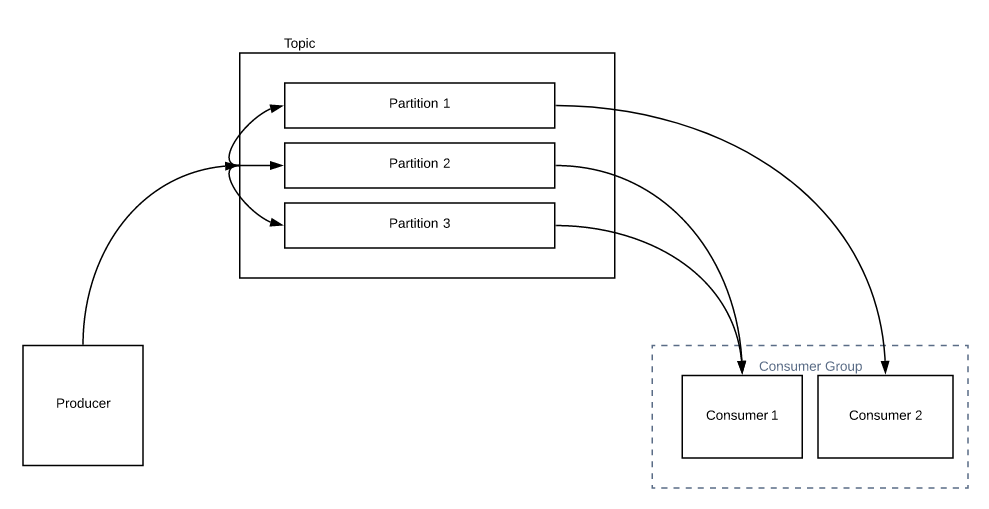

Now the obvious question would be, What happens If I have more number of consumers than the number of partitions.? Each consumer would be assigned 1 partition. Any additional consumers in the group will be sitting idle unless you increase the number of partitions for a Topic.
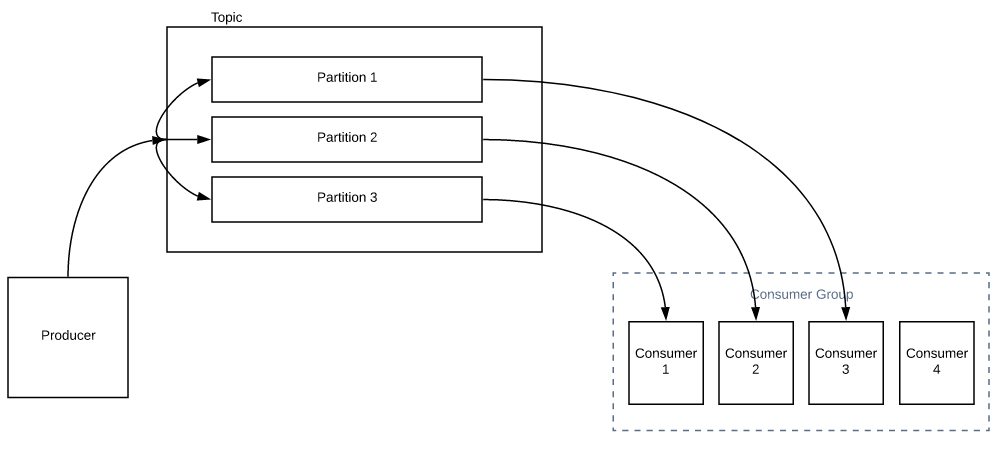

So, we need to choose the partitions accordingly. That decides the max number of consumers in the group. Changing the partition for an existing topic is really not recommended as It could cause issues. That is, Lets assume a producer producing names into a topic where we have 3 partitions. All the names starting with A-I go to Partition 1, J-R in partition 2 and S-Z in partition 3. Now lets also assume that we have already produced 1 million messages. Now if you suddenly increase the number of partitions to 5 from 3, It will create a different range now. That is, A-F in Partition 1, G-K in partition 2, L-Q in partition 3, R-U in partition 4 and V-Z in partition 5. Do you get it? It kind of affects the order of the messages we had before! So you need to be aware of this. If this could be a problem, then we need to choose the partition accordingly upfront.
Main aim of this article is to demo the producer and consumers in a group behavior.
Sequence Number Producer:
We would be using the same code as we saw in the previous article. However instead of random number, we would be generating number sequentially. So that we can understand better what is going on! (The class name is still RandomNumberProducer. But that’s OK)
@Component
public class RandomNumberProducer {
private static final int MIN = 10;
private static final int MAX = 100_000;
private int counter = 1;
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Scheduled(fixedRate = 1000)
public void produce() throws UnknownHostException {
int random = counter++;
this.kafkaTemplate.sendDefault(String.valueOf(random));
//just for logging
String hostName = InetAddress.getLocalHost().getHostName();
System.out.println(String.format("%s produced %d", hostName, random));
}
}Slow Consumer:
To demo the slow consumer behavior, I am introducing a property message.processing.time in the consumer application.
spring:
kafka:
bootstrap-servers:
- localhost:9091
- localhost:9092
- localhost:9093
consumer:
group-id: random-consumer
auto-offset-reset: earliest
key-serializer: org.apache.kafka.common.serialization.StringDeserializer
value-serializer: org.apache.kafka.common.serialization.StringDeserializer
message:
processing:
time: 0Now the Spring boot consumer application would be like this. Based on the property value, we would sleep to simulate the slowness!
@Component
public class RandomNumberConsumer {
@Value("${message.processing.time}")
private long processingTime;
@KafkaListener(topics = "random-number")
public void consumer(String message) throws UnknownHostException, InterruptedException {
String hostName = InetAddress.getLocalHost().getHostName();
System.out.println(String.format("%s consumed %s", hostName, message));
Thread.sleep(processingTime);
}
}Dockerizing Producer:
- I create a Dockerfile in the producer application as shown here.
- I have added a environment variable called BROKER to override the brokers list we have in the application.yml file.
# Use JRE8 slim
FROM openjdk:8u191-jre-alpine3.8
# Add the app jar
ADD target/*.jar producer.jar
ENTRYPOINT java -jar producer.jar \
--spring.kafka.bootstrap-servers=$BROKER- Run the below command to produce the fat jar with all the dependencies for the spring boot producer application.
mvn clean package
- Then below command to create a docker image for this application.
docker build -t vinsdocker/kafka-consumer .
Dockerizing Consumer:
- The process is almost same as the above producer. But we have one more environment variable to pass the message processing time to simulate the slow behavior.
# Use JRE8 slim
FROM openjdk:8u191-jre-alpine3.8
# Add the app jar
ADD target/*.jar consumer.jar
ENTRYPOINT java -jar consumer.jar \
--spring.kafka.bootstrap-servers=$BROKER \
--message.processing.time=$MESSAGE_PROCESSING_TIME- Run the below command to produce the fat jar with all the dependencies for the spring boot consumer application.
mvn clean package
- Then below command to create a docker image for this application.
docker build -t vinsdocker/kafka-consumer .
Producer & Consumer Group Demo:
- I created a separate directory with 2 yaml files.
- 1 file is for Kafka-cluster. I name the file as kafka-cluster.yaml. The content is same as the one which you have seen in the previous article for creating Kafka cluster.
- 2nd file is for the producer and consumer application. I name it as producer-consumer.yaml

- We can combine these 2 into a single file as well.
- Below is the content of the producer-consumer.yml file.
version: '3'
services:
producer:
image: vinsdocker/kafka-producer
environment:
- BROKER=kafka1:19091
consumer:
image: vinsdocker/kafka-consumer
environment:
- BROKER=kafka2:19092
- MESSAGE_PROCESSING_TIME=0In the above yml file, We have 2 services, 1 for producer and 1 for consumer. Both services need the list of brokers. We do not use localhost:9091 etc here as it is because when you run these services via docker-compose , docker creates a network and places all the services like zookeeper, kafka1, kafka2, kafka3, producer and consumer in the same network. So they find each other by their service name. If you take a look at the kafka broker services, they are listening on ports kafka1:19091, kafka2:19092, kafka3:19093 etc. So these can be passed as broker list. Also the message processing time value is passed as 0 for now.
- First start the kafka cluster using below command.
docker-compose -f kafka-cluster.yml up
- Create the random-number topic with 3 partitions using the Kafka manager (do note that all these steps have been already discussed)
- Open a different terminal for producer-consumer. Then run the below command.
docker-compose -f producer-consumer.yml up
- Once the consumer has started and it would receive partition assignments as shown below. As we have only one consumer, all the partitions have been assigned to this consumer.
![]()

- Once the producer has started producing numbers every second. If you take a look at the terminal, we can also see the messages being consumed by the consumer immediately.

- Lets update the message processing time of the consumer to 2000 milliseconds. So that consumer can not process all the messages and we can see if we can scale the consumers out to fix the problem.
version: '3'
services:
producer:
image: vinsdocker/kafka-producer
environment:
- BROKER=kafka1:19091
consumer:
image: vinsdocker/kafka-consumer
environment:
- BROKER=kafka2:19092
- MESSAGE_PROCESSING_TIME=2000- Stop the containers by pressing ctrl+c on the producer-consumer terminal. Rerun the below command.
docker-compose -f producer-consumer.yml up
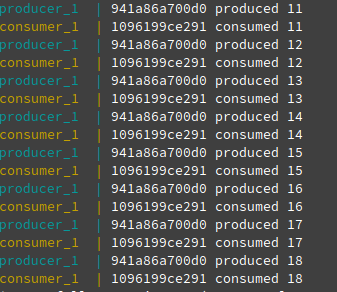
- Take a look at the terminal. While the producer is at 35, 36, our consumer is still at 15. In this rate, it can not process all the messages.


- Stop the containers by pressing ctrl+c on the producer-consumer terminal. Run the below command to start 2 consumers. Lets see if it can fix the problem.
docker-compose -f producer-consumer.yml up --scale consumer=2
- If you take a look at the log, We have 2 consumers (consumer_1, consumer_2). Partitions 0 and 1 have been assigned to consumer_1 and Partition 2 has been assigned to consumer_2.


- As the message processing time is 2 seconds and we have 2 only consumers, still we are not able to read all the messages. consumer_2 seems to be OK as it has only one partition. consumer_1 gets the data from 2 partitions – it does not seem to be processing the latest messages.
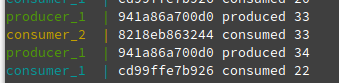

- Stop all the containers. Lets increase the number of consumers to 3 by using the scale option of docker-compose. Check the below partitions assignment. Each consumer is assigned with 1 partition.
docker-compose -f producer-consumer.yml up --scale consumer=3


- Check the below image which shows as and when producer produces a message, one of the consumers from the group consumes the message immediately.
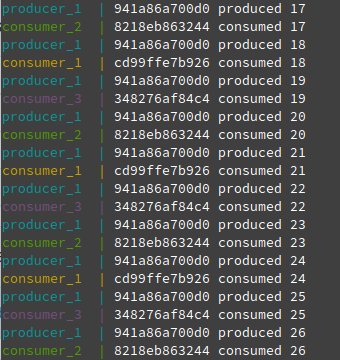

- What happens if we run 4 instances of the consumers in the group.?
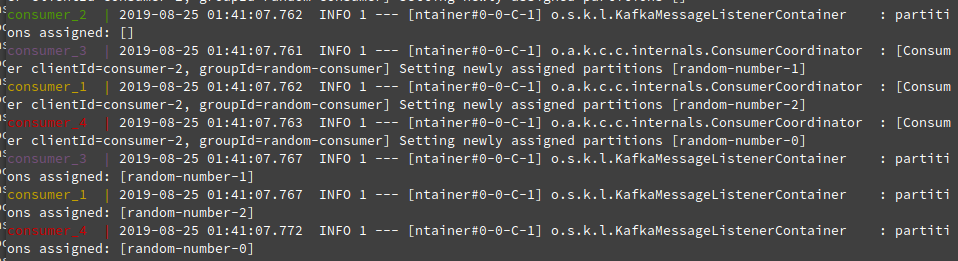
docker-compose -f producer-consumer.yml up --scale consumer=4
- If you see the log, consumer_2 does NOT have any partitions assigned. It would be sitting idle as there are only 3 partitions but we have 4 consumers in the group!

Summary:
When the consumer’s throughput is lesser than the producer’s throughput, then we will NOT be able to process all the messages in the Kafka topic. If we have more partitions, then we can scale the consumer out for a consumer-group to match producer’s throughput.
{kind=link}