



Overview:
In this tutorial, I would like to show you passing messages between services using Kafka Stream with Spring Cloud Stream Kafka Binder.
Spring Cloud Stream:
Spring Cloud Stream is a framework for creating message-driven Microservices and It provides a connectivity to the message brokers. Something like Spring Data, with abstraction, we can produce/process/consume data stream with any message broker (Kafka/RabbitMQ) without much configuration. The producer/processor/consumer is simplified using Java 8’s functional interfaces.
| Application Type | Java Functional Interface |
|---|---|
| Kafka Producer | Supplier |
| Kafka Consumer | Consumer |
| Kafka Processor | Function |
Normally when we use the message broker for passing the messages between 2 applications, developer is responsible for message channel creation, type conversion – serialization and deserialization etc. Spring Cloud Stream takes care of serialization and deserialization, assumes configuration, creates topics etc. So that developer can focus on the business logic and need not worry about the infrastructure.
Sample Application:
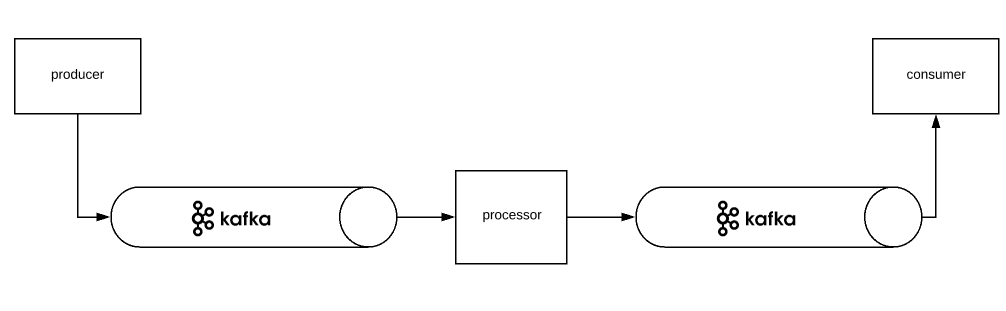

- Producer publishes number starting from 1 every second
- Processor – just squares the given number. (If it receives 3, it will return 9)
- Consumer just prints the number received
Kafka Set up:
Take a look at this article Kafka – Local Infrastructure Setup Using Docker Compose, set up a Kafka cluster. Once done, create 2 topics.
-
- numbers (Topic 1 / Source topic)
- squares (Topic 2 / Sink topic)
Spring Boot – Project Set up:
- Create a simple spring boot application with below dependencies.

Spring Cloud Stream – Producer:
This method with couple of lines acts as a producer. (You can use any type T. But the return type should be Supplier<T>). I would like to publish a number every second. So I have used Flux.interval. Supplier is responsible for publishing data to a Kafka topic. (Topic configuration is part of the configuration file)
@Bean
public Supplier<Flux<Long>> producer(){
return () -> Flux.interval(Duration.ofSeconds(1))
.log();
}Spring Cloud Stream – Processor:
This function will act as a processor. It consumes the data from a Kafka topic, processes data and sends it to another topic.
@Bean
public Function<Flux<Long>, Flux<Long>> processor(){
return longFlux -> longFlux
.map(i -> i * i)
.log();
}Spring Cloud Stream – Consumer:
Here we consume the data from a Topic.
@Bean
public Consumer<Long> consumer(){
return (i) -> {
System.out.println("Consumer Received : " + i);
};
}If you see the above methods, they are very simple and easy to understand. We do not have to deal with Kafka libraries as they are all taken care by Spring Cloud Stream Kafka Binder.
Now, the next obvious question would be – Where is this data getting published? How does Spring Cloud Stream Kafka Binder assume the message channel name / topic names. ? This is where the auto-configuration comes into picture.
Spring Cloud Stream – Configuration:
We have created below beans. The name of the beans can be anything. It does not have to be exactly as I have shown here.
- producer
- processor
- consumer
The application.yaml should be updated with the beans. Spring Cloud Stream treats them as producer or processor or consumer based on the Type (Supplier / Function / Consumer).
spring.cloud.stream:
function:
definition: producer;processor;consumerHere I have semi-colon separated the names as our application has 3 beans. If your application has only one, just give 1.
By default, Spring Cloud Stream creates below topics with below names.
- For producer
- [producer-name]-out-0
- For processor, 2 topics would be created. One for incoming and one for outgoing.
- [processor-name]-in-0
- [processor-name]-out-0
- For consumer
- [consumer-name]-in-0
In our case, We would like to use our custom names for the topics. Also, producer output channel should be same as processor input channel. Processor output channel should be same as Consumer’s input channel. Spring cloud stream simplifies that by allowing us to have a configuration like this in the application.yaml.
spring.cloud.stream:
bindings:
producer-out-0:
destination: numbers
processor-in-0:
destination: numbers
processor-out-0:
destination: squares
consumer-in-0:
destination: squaresDemo:
That’s it! We can run the application now.
If I run my application, I see the output as shown below. Spring automatically takes care of all the configuration. We are able to produce, process and consume data very quickly without much configuration using Spring Cloud Stream Kafka Binder.
2020-04-23 01:16:43.615 INFO 23389 --- [ parallel-1] reactor.Flux.Interval.2 : onNext(7)
2020-04-23 01:16:43.622 INFO 23389 --- [container-0-C-1] reactor.Flux.Map.1 : onNext(49)
Consumer Received : 49
2020-04-23 01:16:44.615 INFO 23389 --- [ parallel-1] reactor.Flux.Interval.2 : onNext(8)
2020-04-23 01:16:44.622 INFO 23389 --- [container-0-C-1] reactor.Flux.Map.1 : onNext(64)
Consumer Received : 64
2020-04-23 01:16:45.615 INFO 23389 --- [ parallel-1] reactor.Flux.Interval.2 : onNext(9)
2020-04-23 01:16:45.620 INFO 23389 --- [container-0-C-1] reactor.Flux.Map.1 : onNext(81)
Consumer Received : 81
2020-04-23 01:16:46.615 INFO 23389 --- [ parallel-1] reactor.Flux.Interval.2 : onNext(10)
2020-04-23 01:16:46.621 INFO 23389 --- [container-0-C-1] reactor.Flux.Map.1 : onNext(100)
Consumer Received : 100Summary:
We were able to successfully demonstrate services communication with Spring Cloud Stream Kafka Binder. The services are completely decoupled and able to communicate via Kafka Stream.
Learn more about Kafka.
- Kafka Stream With Spring Boot – Real Time Data Processing
- Microservice Pattern – Choreography Saga Pattern With Spring Boot + Kafka
- Microservice Pattern – Orchestration Saga Pattern With Spring Boot + Kafka
The source code of this demo is available here.
Happy learning 🙂
{kind=link}